Linked List (Simply Linked List)
리스트(List)는 데이터를 순서대로 나열한 자료구조이다.
앞서 공부하였던 자료구조1의 Stack과 Queue역시 리스트의 구조로 되어있다.


리스트는 일반 선형리스트(Array List)와 연결리스트(Linked List)로 볼 수 있다. 일반 선형리스트는 연속된 공간에 데이터가 차례로 쌓이며, 연결리스트의 경우 각 노드(data)가 비 연속적인 공간에 다음 node를 가르키는 포인터공간과 함께존재한다.
실제 자료공간의 활용예시는 아래 사진을 참조하였다.
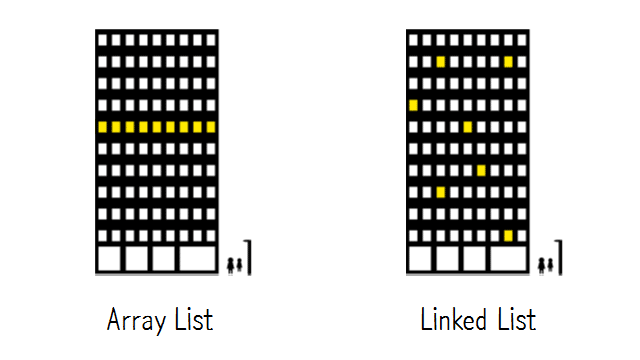
일반 ArrayList 의 경우 정적인 메모리 형태를 갖고있다.
랜덤 엑세스가 빠르지만, 메모리(공간) 사용에 비효율적이며, 데이터가 공간에 차례대로 배정되어있으므로, 데이터의 삽입, 삭제에 따라 데이터를 모두 옮겨야 하기 때문에 효율이 좋지 않다.
Linked List 의 경우 동적으로 메모리를 사용한다.
메모리(공간)을 효율적으로 사용할 수 있다. 또한 데이터 재구성이 용이하여 대용량 데이터 처리에 적합하다.
하지만 데이터 탐색에 느리며(중간 노드 탐색의 경우) 구현이 까다롭다는 단점이 있으며, 데이터 저장공간뿐만아니라 다음 노드 주소의 저장공간이 추가적으로 필요하다는 단점이 있다.
Linked List는 Array List 와는 다르게 각각의 노드(node, 혹은 요소_element)가 연결되어 있다는 특징이 있다.
각각의 노드는 데이터와 다음 노드를 가리키는 포인터를 가지고 있다.
처음과 끝에 있는 노드는 각각 머리노드(head node), 꼬리노드(tail node)라고한다.
하나의 노드에 대해 바로 앞에있는 노드를 앞쪽노드(predecessor node),바로 뒤에 있는 노드를 다음노드(successor node)라고 한다.

Head노드의 참조주소가 반드시 필요하며, (파일 손상으로)주소를 잃어버릴경우 데이터 전체를 못쓰게 되는 단점이 있다.따라서 안정적인 자료구조는 아니다.
포인터로 연결 리스트 만들기
import java.util.Comparator;
public class LinkedList<E>{
class Node<E>{
private E data; //데이터
Node<e> next; //뒤쪽 포인터(다음 노드 참조)
//이러한 클래스 구조를 자기참조(self-referential)형 이라고 한다.
}
private Node<E> head; //머리노드
private Node<E> crnt; //선택노드
Node(E data, Node<E> next){
this.data = data;
this.next = next;
}
public LinkedList(){
head = crnt = null;
}
public E search(E ojb, Coparator<? super E> c){
Node<e> ptr = head;
while (ptr != null){
if(c.compare(obj, ptr.data) == 0){//검색 성공
crnt = ptr;
return ptr.data;
}
ptr = ptr.next;
//다음 노드를 선택
}
return null; 검색 실패
}
public void addFirst(E obj){
Node<e> ptr = head;
head = crnt = new Node<e>(obj, ptr);
}
pbulic void addLast(E obj){
if(head == null) addFirst(obj);
else{
while(ptr.next != null) ptr = ptr.next;
ptr.next = crnt = next Node<e> (obj, null);
}
}
/*
.
.
.
.
.
이하 메소드 생략
*/
}
// 위 사진과 구조가 같다면, 노드가 0개일때는
head == null
// 노드가 1개일 때에는
head.next == null
// 노드가 2개일 때는
head.next.next == null
// 꼬리노드라면
p.next == null
//일것이다!Search : 검색을 수행
seach메서드는 조건을 만족하는 노드를 검색한다. 검색에 사용되는 알고리즘은 선형검색이고, 검색할 노드를 만날 때 까지 머리노드부터 스캔한다.
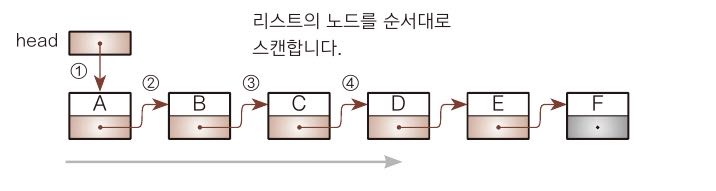
노드 스캔의 종료 조건은 아래 두가지이다.
- 검색 조건을 만족하는 노드를 찾지 못하고 꼬리 노드를 지나가기 직전인 경우
- 검색 조건을 만족하는 노드를 찾은 경우
addFirst : 머리에 노드를 삽입
- 삽입 전 머리노드에 대한 포인터를 ptr에 대입한다.
- 삽입할 노드를 new<e>(obj,ptr)에 의해 생성하며, 노드의 데이터는 obj가 되고 뒤쪽 포인터가 가리키는 곳은 ptr이된다. 생성한 노드를 참조하도록 head를 업데이트한다.
addLast : 꼬리에 노드를 삽입
리스트가 비어있는가? addFirst : 리스트 꼬리에 노드를 삽입removeFirst : 머리노드 삭제
head 와 crnt 를 두번째 노드(head.next)로 업데이트한다.
리스트가 비어있을 경우를 제외하곤, 에러상황 없음.
removeLast : 꼬리노드 삭제
리스트에 노드가 하나 이상인가?
리스트에 노드가 2개 이상인가? removeLast : removeFirst;Simply Linked List 는 순방향탐색만 가능하므로, 꼬리노드에서 이전 노드를 탐색할수없다.
removeLast는 꼬리노드와 그 이전노드를 선방향으로 다시 탐색하여 이전노드의 포인터를 null로 할당한다.
remove : 선택한 노드 삭제
//삭제할 노드가 머리노드인가? removeFirst : remove
Node<e> ptr = head;
while(ptr.next != p) {// p: 삭제할 노드
ptr = ptr.next;
if(ptr == null) return;
}
ptr.next = p.next;
crnt = ptr;removeCurrentNode : 선택 노드를 삭제
앞서구현한 remove와 crnt를 이용
clear : 모든 노드 삭제
여러가지 방법이 있겠지만, 노드에 아무것도 없을 때 까지 머리노드를 삭제하는것이 효율적일것이다.
next : 선택노드 다음 노드로 이동
crnt(선택노드)를 하나 이동시키며, 이동에 성공하면 true로, 실패(리스트가 비어있거나, 꼬리노드일경우)시 false를 반환.
printCurrentNode : 선택 노드 출력
dump : 모든 노드를 출력
선방향으로 재 순환하며모든 data 를 출력함
Tree

트리구조는 데이터 사이의 계층관계를 나타내며, 그래프의 일종이다.
트리는 여러 노드가 한 노드를 가르킬 수 없는 구조이다.
트리구조는 비선형구조인데, 이는 하나의 자료 뒤에 여러개의 자료가 존재할 수 있음을 의미하기도 한다.
정점(node)와 선분(branch)로 이루어져있으며, 사이클을 이루지 않는다.
또한 계층(부모, 자식) 구조를 이루며 방향성이 있다.
주요 용어
- Node : 노드, 구성요소
- Edge : 노드와 노드를 연결하는 연결선
- Root Node : 노드 A, 트리구조의 최상위
- leaf : 리프, 더이상 뻗어나가지 않는 마지막 노드에 위치하는 노드
- Non-terminal node : 안쪽 노드, 루트를 포함하여 리프를 제외한 노드
- Termianl Node (Leaf Node) : 밑으로 다른 노드가 연결되어 있지 않은 H, I, J, F, G와 같은 노드
- sibling : 형제노드 - 같은 부모를 가지는 노드
- ancestor : 조상 노드 - 가지로 연결된 위쪽 노드는 모두 조상이다.
- descendant : 자손 - 가지로 연결된 아래쪽 노드는 모두 자손이다.
- Height : 트리의 최고레벨
- degree : 차수 - 노드가 갖는자식의수
- height : 높이 - 루프로부터 가장 멀리떨어진 리프까지의 거리
- Level : 트리에서 각 층별로 숫자를 매김
- Sub-Tree : 큰트리에 속하는 작은트리
- null tree : 노드, 가지가 없는 트리
- ordered tree, unordered tree : 순서트리, 무순서트리 - 형제노드의 순서를 따지면 순서트리, 그렇지 않다면 무순서트리이다.
순서트리 탐색
순서 트리의 노드를 스캔하는 방법은 두가지이다.
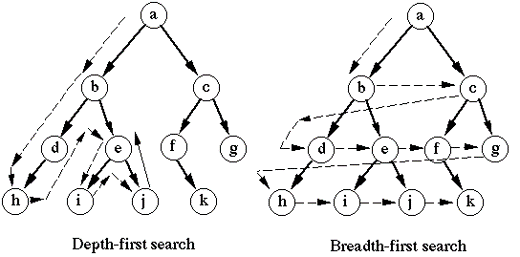
- 너비 우선 탐색(Breadth-first search)
낮은 레벨에서 시작해, 왼쪽에서 오른쪽 방향으로 검색하고한 레벨에서 검색이 끝나면 다음 레벨로 내려간다. - 깊이 우선 탐색(Dept - first search)
리프까지 내려가며 검색하는것을 우선순위로 탐색한다.
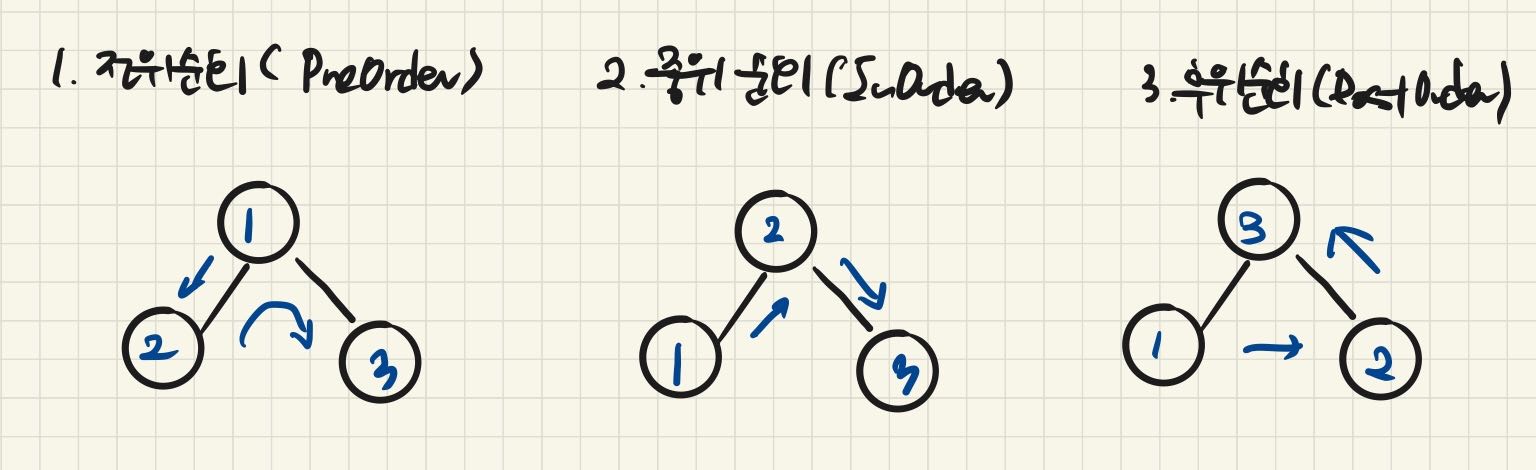
'어떤 노드를 더 우선순위로 갈것인가? 는 아래 세 종류로 구분한다.
- Preorder - 전위 순회 : 노드 -> 왼쪽자식 -> 오른쪽자식
- Inorder - 중위 순회 : 왼쪽자식 -> 노드 -> 오른쪽자식
- Postorder - 후위 순회 : 왼쪽자식 -> 오른쪽자식 -> 노드

Bianary Tree

이진트리는 위 그림과 같이 노드가 왼쪽 자식과 오른쪽 자식을 갖는 트리이다. 차수가 2이하이어야 성립된다.
complete binary tree : 완전이진트리
완전이진트리는 왼쪽부터 오른쪽으로 노드가 채워진다. 마지막 레벨이 아니면 노드가 가득채워져있어야하지만, 마지막 레벨이라면 왼쪽부터 노드를 채우기만 하면 되며 반드시 모두 채워져있지 않아도 된다.
Binary Search Tree (이진 검색트리)
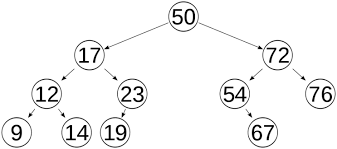
이진검색트리는 이진트리가 다음 조건을 만족해야한다.(위 사진과 함께 참조)
- 어떤 노드 N을 기준으로 왼쪽 서브 트리 노드의 모든 키값은 노드 N의 키 값보다 작아야 한다.
- 오른쪽 서브 트리 노드의 키 값은 노드 N의 키 값보다 커야한다.
- 같은 키 값을 갖는 노드 값은 없다.
이진 검색트리는 중위 순회를 하면 키값의 오름차순으로 노드를 얻을 수 있다는 점과 구조가 단순하다는 점, 이진검색과 비슷한 방식으로 검색이 가능하다는 점, 노드의 삽입이 쉽다는 점의 장점이 있어 폭넓게 사용된다.
(이진검색 : 크기순으로 정렬된 배열에서 배열의 중간의 값으로 좌,우측을 탐색하는 탐색알고리즘)
import java.util.Comparator;
public class BinTree<K, V>{
static class Node<K,V>{
private K key; // 키 값
private V data; // 데이터
private Node<K, V> left; // 왼쪽 자식노드
private Node<K, B> right; //오른쪽 자식노드
//생성자
Node(K key, V data, Node<K,V> left, Node<k,V>right){
this.key = key;
this.data = data;
this.left = left; // left포인터와
this.right = right; // right포인터가 각자 존재
}
K getKey(){
return key;
}
V getValue(){
return data;
}
void print(){
System.out.println(data);
}
}
private Node<K,V> root; // root
private Comparator<? super K> comparator = null;// 비교자
//루트에 대한 참조인 root를 null로하여 노드가 하나도 없는 이진트리를 생성
public BinTree(){
root = null;
//어떤 노드도 가르키지 않음
}
//생성자
public BinTree(Comparator<? super K> c){
this();//BinTree()호출,root가 null인 이진검색트리 생성
comparator = c; //전달받은 c설정
}
//두 값을 비교
private int comp(K key1, K key2){
return (comparator == null) ? ((Comparable<K>key1)).compareTo(key2) : comparator.compare(key1, key2);
//comparator.compare(key1, key2) -> key1 > key2면 양수, key1 < key2 면 음수, Key1 === key2 면 0
// (Comparable<K>key1)).compareTo(key2)->비교자 설정 없음.
}
}여기에서 comparator 기억이 안나서 엄청헤멤..
Search : 검색 알고리즘
- root 노드로 시작한다.
- node vlaue 와 비교하여 작다면 왼쪽으로 검색을 진행, 크다면 우측으로 검색을 진행한다.
- 일치하는 값이 없다면 검색 실패
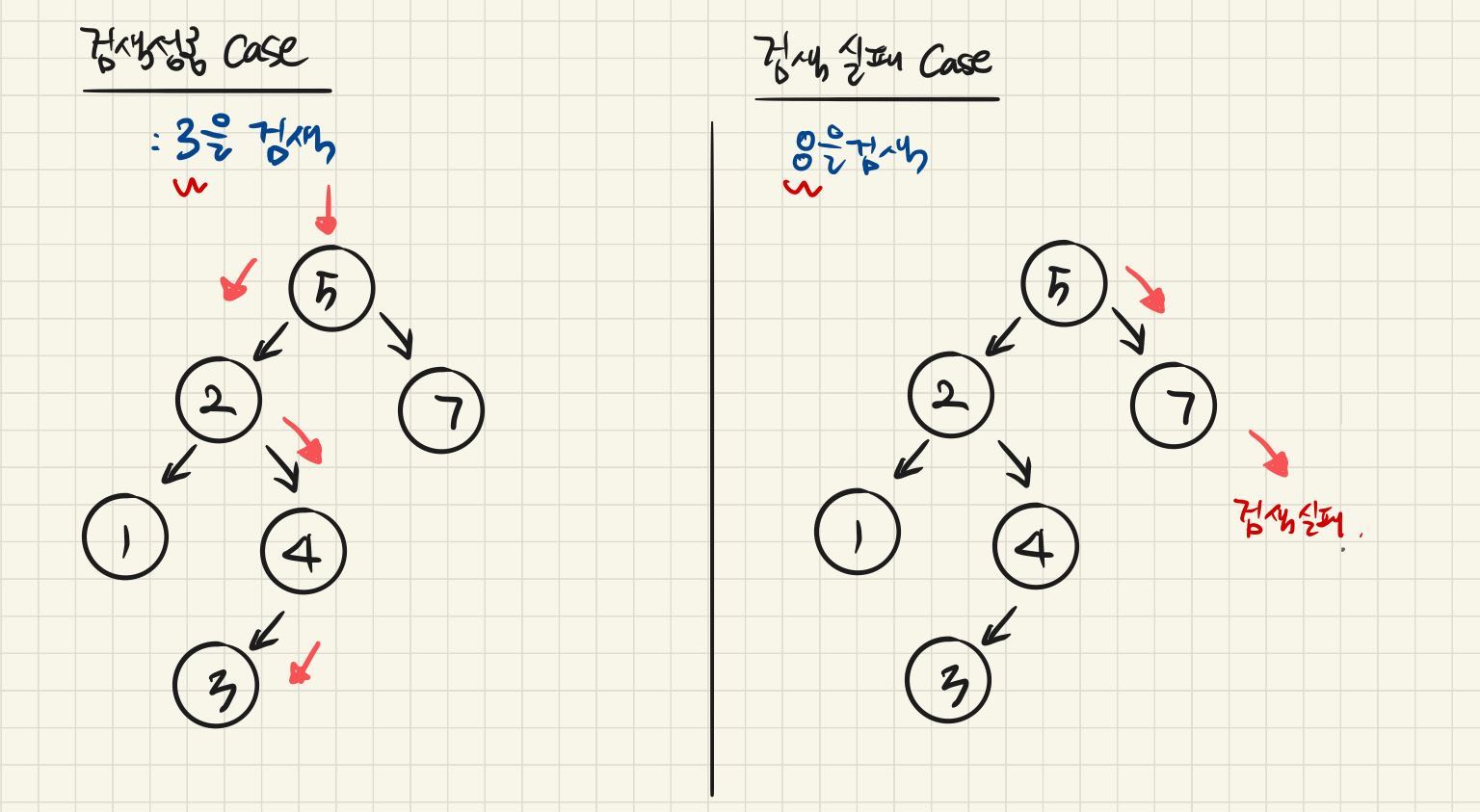
코드로 표현
public V search(K key){
Node<K,V> p = root;
while(true){
if(p ==null) return null; //더이상 진행하지 않으면 검색실패
int cond = comp(key, p.getKey());//key와 노드 p를 비교
if(cond == 0) return p.getValue(); //값이 일치하는 경우 return
else if(cond < 0) p = p.left; // 작다면 left
else p = p.right; //크다면 right
}
}addNode : 노드를 삽입
- 루트부터 시작
- 삽입할 Key와 node의 키 값을 비교, 값이 같다면 삽입에 실패
leaf까지 도달하여 값을 비교하여 왼쪽 혹은 오른쪽 node에 추가
remove : 노드를 삭제
- 자식 노드가 없는 경우를 삭제하는 경우
search 와 같이 탐색후 부모노드의 해당 포인터를 null로 설정 - 자식 노드가 1개인 노드를 삭제하는경우
삭제 대상의 노드가 왼쪽자식이면 왼쪽 포인터가 삭제 대상 노드의 자식을 가르키도록,
오른쪽 자식이면 오른쪽 포인터가 삭제 대상 노드의 자식을 가르키도록함 - 자식노드가 2개인 노드를 삭제하는 경우-아래사진을참고
- 삭제할 노드의 왼쪽 서브트리에서 키 값이 가장 큰 노드를 검색함
- 검색한 노드를 삭제위치로 옮김
- 옮긴 노드를 삭제

print : 모든 노드를 출력
재귀적인 방식이 필요함
private void printSubTree(Node node){
if(node != null){//입력받은 노드가 null이 아닐때만 작동하고, 재귀호출이 이어짐
printSubTree(node.left);// 왼쪽 서브 트리를 키 값의 오름차순으로 출력
System.out.println(node.key+" "+ node.data);//node를 출력
printSubTree(node.right); //오른쪽 서브트리를 키 값의 오름차순으로 출력
}
public void print(){
printSubTree(root);
}
}Graph(NonLinear)

그래프는 위에서 학습한 트리에서 root->reef의 방향성이 없어지고, 심지어 edge가 자기자신을 가르키기도 하는 형태이다.(트리는 그래프의 한 종류이며, 트리가 되기위해선 몇가지 제한 상황이 있다.)
그래프는 방향성이 있을수도 (directed graph) 방향성이 없을수도( undirected graph) 있다.
(트리틑 directed graph 이다.)
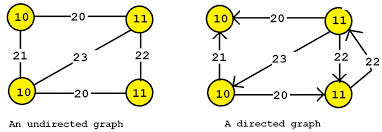
또한 그래프 내에서 순환구조(Cyclic graph)가 있을수도, 순환구조가 있지 않을수도(Acyclic graph) 있다.
Graph를 표현하는 방법
- Adjacency Matrix - 2차원 배열(표)로 표현하는 방법
- Adjacency List -배열의 node들을 나열하고 관계를 linked list로 표현하는 방법

- Adjacency Matrix : 서로 연결이 되어잇다면 1, 그렇지 않다면 0 으로 표현하는 방법
- Adjacency List : 배열 방에 모든 Node들을 하나씩 집어넣고, 각 배열방에 있는 해당 노드와 인접한 노드들을 linked list 로 쭉 집어넣는것! -> 2n개 생성
Search : 검색 메소드
- DFS - Depth - Fist Search : 깊이 우선검색
- BFS - BreadTh-First Search : 너비 우선 탐색_level별로 검색
위 DFS, BFS 트리에서와 같으니 detail은 tree 의 디테일을 참고하자!
1. DFS: Stack으로 구현 - 링크
- 한번 stack 에 쌓았던 node는 더이상 stack 에 넣지 않음
출발Node를 stack 에 쌓음 -> 해당노드를 stack 에서 꺼내어 자식노드를 모두 stack 에 쌓음 -> stack에서 꺼내어 출력하며 해당 노드의 자식을 stack 에 쌓음 ->stack 에 남은 node가 없을때까지 반복하면 DFS Search가 완성됨
-Recursion을 이용하면 깔끔한 구현이 가능하다.
class Queue<T>{//이전에 구현헌 Queue를 사용
}
class Grph{
class Node{
int data;//node의 데이터
LinkedList<Node> adjacent;//인접노드는 LinkedList로표현
boolean marked;//방문했는지 mark할 함수
Node(int data){//생성자
this.data = data;
this.marked = false;//marking flag초기화
adjacent = new LinkedList<Node>();
}
}
Node[] nodes;//그래프를 저장할 배열
Graph(int size){//간단한 구현을 위해 graph node고정
nodes = new Node[size];
for(int i = 0 ; i < size ; i++){
nodes[i] = new Node(i);
}
}
void addEdge(int i1, int i2){//edge추가
Node n1= nodes[i1];
Node n2= nodes[i2];
//두개에 노드에 인접한 노드를 저장하는 linked list 에 서로 존재하는지 확인하고, 없다면 추가해줌.
if(!n1.adjacent.contains(n2)){
n1.adjacent.add(n2);
}
if(!n2.adjacent.contains(n1)){
n2.adjacent.add(n1);
}
}
void dfs(){//그냥 호출하면 0 번부터 시작
dfs(0);
}
void bfs(){
bfs(0);
}
void dfs(int index){//시작 Index 를 받아서 dfs를 출력
Node root = nodes[index];
Stack<Node> stack = new Stack<Node>();
stack.push(root);//현재 Node를 stack 에 추가
root.marked = true;
while(!stack.isEmpty()){
//stack 데이터가 없을때까지 반복
if(n.marked == false){//stack 에 없는 node만!
n.marked = true;
stack.push(n);
}
}
visit(r);
}
void bfs(int index){
Node root = nodes[index];
Queue<Node> queue = new Queue<Node>();
queue.enqueeu(root);//데이터를 queue에 추가
root.marked = true;
while(!queue.isEmpty(){
Node r= queue.dequeue();
for( Node n :r.adjacent){
if(n.marked == false){
n.marked = true;
queue.enqueue(n);
}
}
visit(r);
}
}
//재귀를 이용한 dfs구현
//linked list 가 주소를 포함하고있기때문에 node를 받아야함
void dfsR(Node r){
if(r ==null) return;//leaf일경우 종료
r.marked = true;
visit(r);//데이터 출력
for( Node n : r.adjacent){
if(n.marked == false){
dfsR(n);
}
}
}
void dfsR(int index){
Node r = nodes[index];
dfsR(r);
}
void dfsR(){
dfsR(0);
}
void visit(Node n){
System.out.print(n.data+" ");
}
}
public class Test{
public static void main (String[] args){
//Graph선언 후
//addEdge 로 명시
// dfs();
//bfs();
}
}2. BFS: Queue로 구현
- 한번 큐에 들어갔던 node는 다시 들어가지않는다.
큐에 시작 node를 push -> node를 하나 pop하고 출력. -> 꺼낸 노드의 자식노드를 모두 que에 Push -> Node를 하나 pop-> 남은 Node가 없을때까지 반복하면 BFS가 완성된다.
DFS와 BFS는 기본적으로 search 알고리즘이 비슷하나, DFS는 stack 으로, BFS는 queue로 구현하는데에서 차이가 발생한다.
Hash Table

해시테이블이란 아래와 같은 구조로 data 에 접근하는 자료구조이다.
- 검색하고자 하는 key(문자열, 숫자, file data...)값을 입력받음
- Hash함수를 실행하여 Hash Code를 돌려받음
- Hashcode를 배열의 index로 환산
- 데이터로 접근
여기에서 해시함수는 특정 규칙을 이용하여 입력받은 key값으로 (key값의 크기와 상관없이)동일한 Hash Code를 만들어준다.

해시테이블의 가장 큰 장점은 검색속도가 매우 빠르다는 것이다. - 최소 검색시간 : O(1)
해시 함수를 이용해서 만든 해시코드는 정수의 형태이다.
배열 공간(index)를 고정된 크기만큼 만들어놓고, 해시 코드를 배열의 갯수만큼 나머지 연산을 하여 배열에 나누어 담는다. 즉, 해시코드 자체가 배열의 index로 사용되기때문에 검색자체를 할 필요가 없고 code만으로 index 에 direct 접근을 할 수 있어 빠른 연산이 가능하다.
해시테이블의 list를 만들때 index 에 해당하는 규칙을 잘 만드는 것이 중요하다(Hash Algorithm)
비효율적인 경우 충돌현상(Collison)이 생길수있다.- 최대 검색시간 : O(n)
(만약 충돌이 전혀 발생하지 않는다면 해시 함수로 인덱스를 찾는 것만으로 검색, 추가 ,삭제가 거의 완료되므로 시간복잡도는 어느것이나 O(1)이 된다.
해시테이블을 크게하면 충돌 발생을 억제할 수 는 있지만 다른 한편으로 메모리를 쓸데없이 많이차지한다. 즉, 시간과 공간의 절충(trade-off)라는 문제가 항상 따라다님)
따라서 해시함수의 알고리즘은 입력받은 키를 가지고 분배를 잘 하는것이 중요하다.
Collision 유형
- 해시함수는 서로다른 키값으로 동일한 키값을 만들어내기도 한다. (different keys -> same code)
(key는 문자열이지만 Hashcode는 정수이기 때문에 갯수의 한계가 있음) - 다른 해시코드가 같은 Index를 가르키기도 한다. (different code -> same index)
구현을 위해 필요한 메소드
- getHashCode(key) : 키를 입력받고, 입력받은 key를 해시알고리즘을 통해 해시코드를 만듬
해시테이블의 크기는 소수가 좋으며, 키 값이 정수가 아닌경우 알고리즘에 조금 더 신경을 많이 써야한다.
간단한 예시로 -> 입력받은 문자열의 각 ASCII값을 입력받아 합하여 HashCode를만들 수 있음 - ConverToindex(HashCode) : HashCode를 입력받아 Index를 환산해줌
Hashcode % size(배열방의 size) - 배열방 안에 LinkedList 를 선언하고 데이터가 배열방 안에 할당이 될 때 마다 Linked List 를 추가함
검색요청시 검색할 키를 Hash함수로 만들어 Hashcode로만들고 index로 환산하여 배열에 들어와 Linked List 를 돌면서 찾는 데이터를 반환한다. - search
- remove
- dump -> 모든 내용 출력
참조
엔지니어 대한민국 - [자료구조 알고리즘] 해쉬테이블(Hash Table)에 대해 알아보고 구현하기
Do it! 자료구조와 함께 배우는 알고리즘 입문 자바 편
엔지니어대한민국 - [자료구조 알고리즘] 그래프(Graph)에 대해서
엔지니어대한민국 - [자료구조 알고리즘] Graph 검색 DFS, BFS 구현 in Java
'창고(2021년 이전)' 카테고리의 다른 글
| [JS] OOP - Inheritance patterns_상속 (0) | 2019.11.21 |
|---|---|
| [Java] Comparator (0) | 2019.11.16 |
| [자료구조] Stack & Queue (0) | 2019.11.15 |
| [JS] OOP(Objcet Oriented Programming) (0) | 2019.11.14 |
| [Git] pair programming work flow (0) | 2019.11.11 |


